MUR Blog - Stereo Vision Update 2
In this post we will outline the updates to our stereo perception pipeline, as quite a bit has changed since the last update. We have since received a pair of loan Basler camera units, a 5MP acA2500-60uc colour camera and a 10MP acA3800-14um mono camera, pair with a 5 and 6mm c-mount lens.

These cameras are just a placeholder while we wait for our final camera, a pair of 2.3MP a2A1920-160ucBAS (Sony IMX392) colour cameras from Basler. These cameras were chosen in part due to their horizontal resolution of 1920 pixels, allowing them to compete with higher resolution cameras, as for our application a horizontal resolution is much more important than vertical.
https://drive.google.com/file/d/195nwbBPiIuW9ObKvEEfGvojYWszizBLz/view
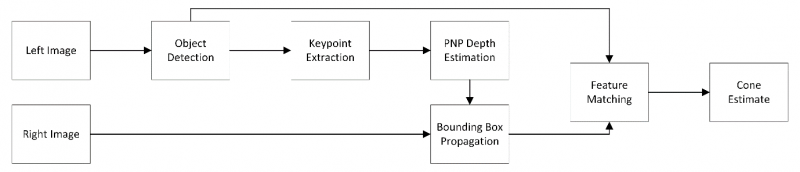
From the last stereo vision update an implementation in which it was assumed that the bounding boxes for cones were available for both the left and right images. With the arrival of the loan cameras, an alternative pipeline as presented by AMZ Driverless (2019) is adopted. In which object detection is only done on one camera. An initial depth is estimated via a perspective-n-point (PNP) algorithm with the use of a keypoint extraction neural net of detected cones with knowledge of the cone’s geometry. This allows us to simply propagate the bounding box in the initial frame to the secondary frame using the simple disparity/distance relationships. With the estimated bounding box in both the left and right frame, a feature extractor like SIFT or SURF is used for disparity refinement in order to attain sub-pixel disparity accuracy, this results in a refined depth and thus position estimate of the cones without incurring the cost of running the object detector network twice a frame pair as well as a pairing algorithm as stated in the previous update.
https://drive.google.com/file/d/1rOi3OkaN4M1-4YDPdX4oSFy3oI3fgjNr/view
As seen in the demo videos, the initial depth estimate from PNP is accurate enough for a propagated bounding box to produce a mask for feature extraction, leading to feature extraction via SIFT/SURF. It is also to be noted that the size discrepancy of the cones can be attributed to using mismatched cameras in terms of sensor size as well as the focal distances of lenses, which can lead to improper propagation at close distances.
Currently, the full image pipeline from image rectification to cone estimation for a single cone in image runs at ~15 Hz (67 ms) on a development machine running a Ryzen 5 2600 with a CUDA enabled 1060 3GB. This performance is tentative as we aim to further leverage GPGPU capabilities of the development and deployment (NVidia Xavier) environment.
Next Steps
- Real-world testing, long-range and large number of cones (COVID restrictions pending)
- Pipeline optimisation and further benchmarking
- Porting pipeline into ROS for systems integration
- Benchmark new propagation technique against old “brute-force” method, in terms of performance as well as accuracy.
About the Author:
 Andrew Huang
Andrew Huang
Spatial & Perception Engineer, 2020